Agent 基础知识
AI Agent
来源:https://zhuanlan.zhihu.com/p/1919338285160965135
名词解释
- MCP(Model Context Protocol)
- Agent LLM+记忆+规划技能+工具使用
开发框架
在掌握了Agent的基本原理后,我们需要将这些理论转化为实际可用的代码实现。虽然开发框架并非技术瓶颈,但一个优秀的开发框架能够为我们提供流程编排、状态管理、工具调用等核心能力,大大加速生产级Agent应用的开发进程。目前AI Agent领域的主流框架生态主要集中在Python和Javascript技术栈,例如:OpenAI的Agents SDK、谷歌的Agent Development Kit 、微软的AutoGen、LangChain的升级版LangGraph等。相比之下,基于Golang技术栈的成熟开源框架相对较少。接下来我们将重点介绍两个优秀的Golang框架:Eino和tRPC-A2A-Go,这两个框架都为开发者提供了丰富的功能和特性,帮助我们快速构建生产级的AI Agent应用。
思考框架
思维链(CoT)
思维链(Chain of Thought, CoT)是一种增强大型语言模型(LLM)处理复杂推理任务能力的关键技术。其核心在于引导模型在给出最终答案前,先生成一系列结构化的中间推理步骤——这如同模拟人类解决问题时的逐步思考过程。通过这种方式,LLM能够更深刻地理解问题结构,有效分解复杂任务,并逐步推导出解决方案。这些显式的思考步骤不仅为模型的决策过程带来了透明度和可解释性,方便用户理解和调试。然而,这种方法的代价是,生成冗长的思考链条会增加计算成本和处理延迟。
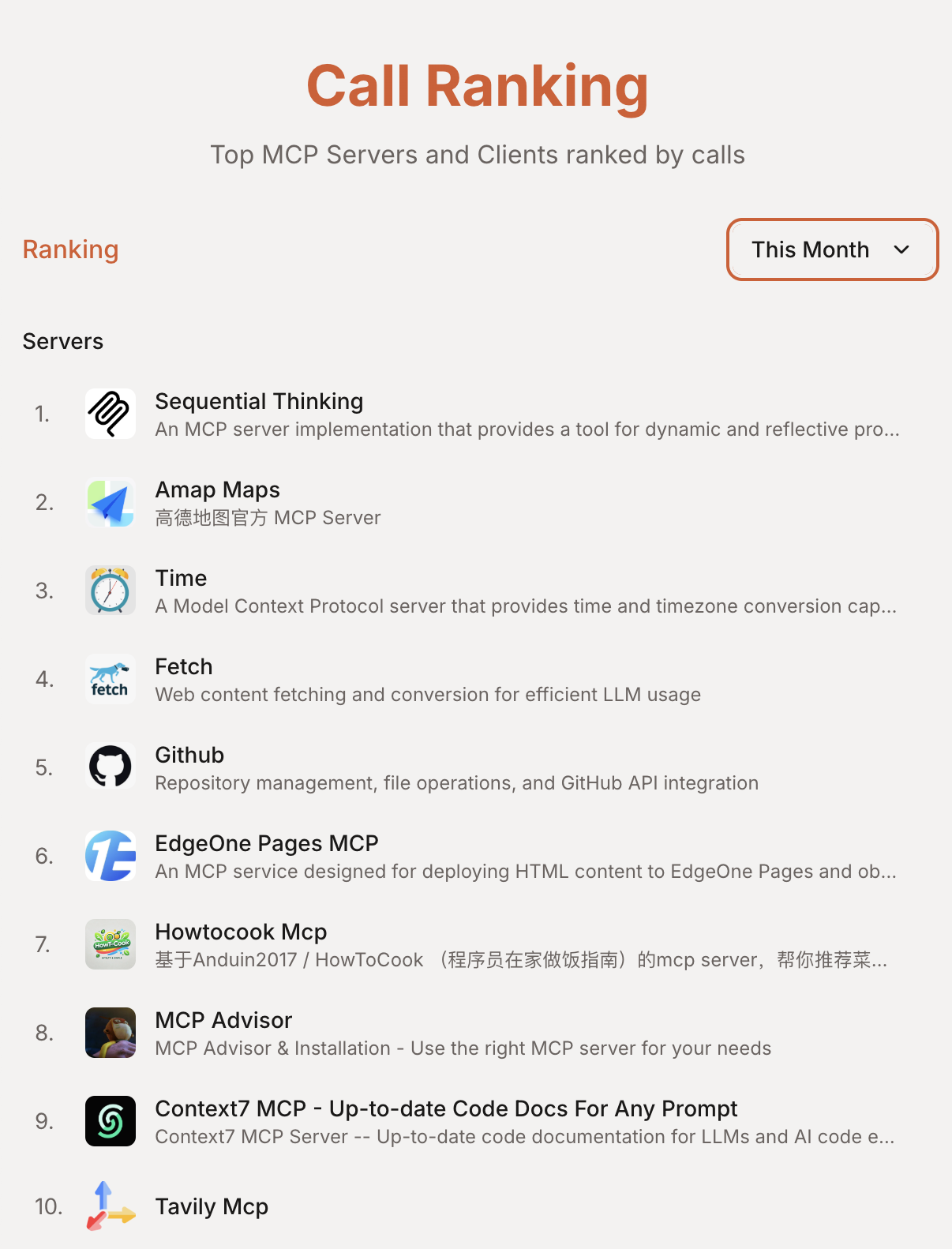
随着DeepSeek R1的深度思考模式验证了思维链对于推理能力的显著提升效果,各大模型厂商纷纷推出了支持慢思考的模型。例如腾讯推出的Hunyuan T1模型、阿里千问推出的QwQ模型。Anthropic官方还开源了Sequential Thinking MCP,它通过精心设计的提示词工程,使得原本不支持慢思考的模型也能实现类似的推理过程。该工具凭借其通用性和易用性,目前已成为使用频率最高的MCP Server(数据来源:https://mcp.so/ranking)。
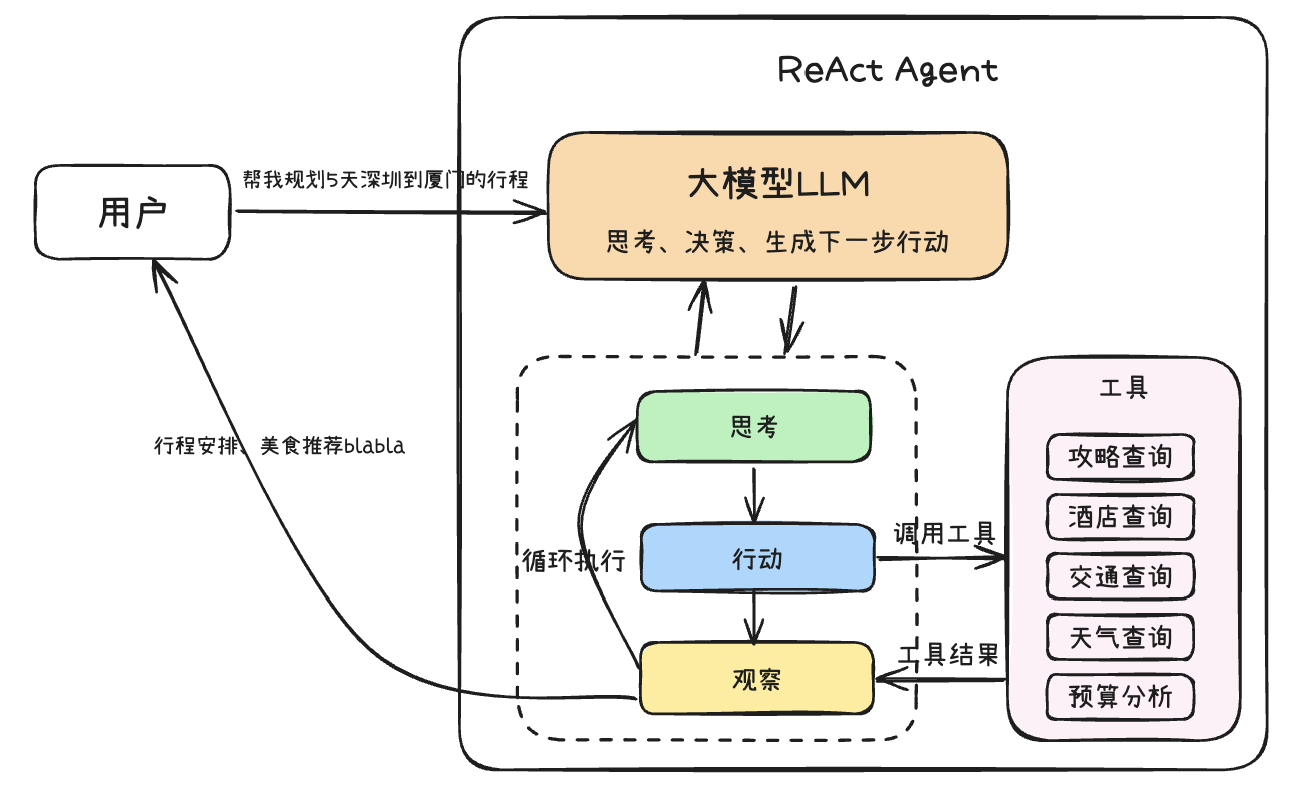
ReAct
CoT虽然增强了模型的推理能力,但其推理过程主要局限于模型内部知识,缺乏与外部世界的实时交互,这可能导致知识陈旧、产生幻觉或错误传播。ReAct(Reasoning and Action)框架通过将”推理”(Reasoning)与”行动”(Action)相结合,有效地解决了这一问题。它允许模型在推理过程中与外部工具或环境进行互动,从而获取最新信息、执行具体操作,并根据反馈调整后续步骤。这种动态的交互赋予了模型一种”边思考边行动、边观察边调整”的能力,其核心运作机制可以概括为思考(Thought)→ 行动(Action)→ 观察(Observation)的迭代循环:
思考 (Thought):模型基于当前任务目标和已有的观察信息,进行逻辑推理和规划。它会分析问题,制定策略,并决定下一步需要执行什么动作(例如,调用哪个工具、查询什么信息)来达成目标或获取关键信息。
行动 (Action):根据”思考”阶段制定的计划,模型生成并执行一个具体的行动指令。这可能包括调用外部API、执行代码片段、查询数据库,或者与用户进行交互等。
观察 (Observation):模型接收并处理”行动”执行后从外部环境(如工具的返回结果、API的响应、用户的回复)中获得的反馈信息。这些观察结果将作为下一轮”思考”的输入,帮助模型评估当前进展、修正错误、并迭代优化后续的行动计划,直至任务完成。
Plan-and-Execute
Plan-and-Execute 是一种对标准 ReAct 框架的扩展和优化,旨在处理更复杂、多步骤的任务。它将 Agent 的工作流程明确划分为两个主要阶段:
规划阶段:Agent 首先对接收到的复杂任务或目标进行整体分析和理解。然后,它会生成一个高层次的计划,将原始任务分解为一系列更小、更易于管理的子任务或步骤。这种分解有助于在执行阶段减少处理每个子任务所需的上下文长度,这个计划通常是一个有序的行动序列,指明了要达成最终目标需要完成哪些关键环节。这个蓝图可以先呈现给用户,允许用户在执行开始前对计划步骤给出修改意见。 执行阶段:计划制定完成后(可能已采纳用户意见),Agent 进入执行阶段。它会按照规划好的步骤逐一执行每个子任务。在执行每个子任务时,Agent 可以采用标准的 ReAct 循环来处理该子任务的具体细节,例如调用特定工具、与外部环境交互、或进行更细致的推理。执行过程中,Agent 会监控每个子任务的完成情况。如果某个子任务成功,则继续下一个;如果遇到失败或预期之外的情况,Agent 可能需要重新评估当前计划,可以动态调整计划或返回到规划阶段进行修正。此阶段同样可以引入用户参与,允许用户对子任务的执行过程或结果进行反馈,甚至提出调整建议。
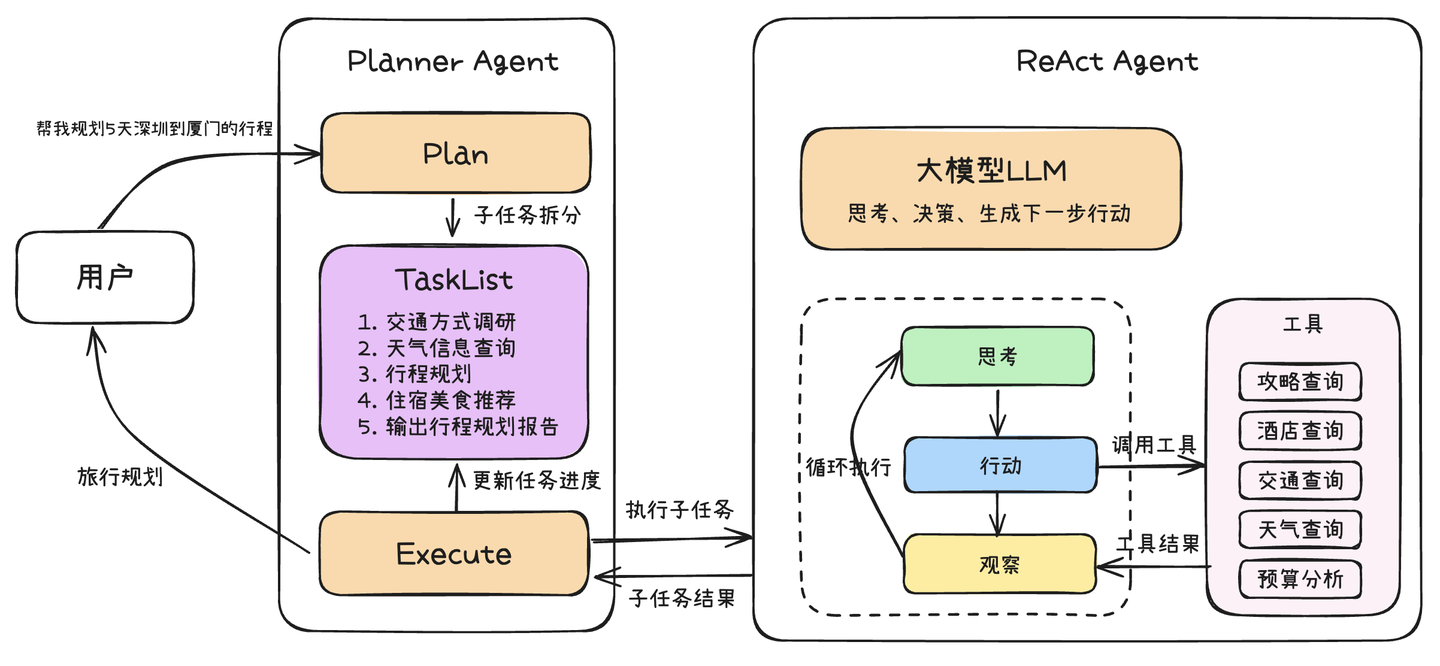
与标准的 ReAct 相比,Plan-and-Execute 模式的主要优势在于:
结构化与上下文优化:通过预先规划将复杂任务分解为小步骤,不仅使 Agent 行为更有条理,还有效减少了执行各子任务时的上下文长度,提升了处理长链条任务的效率和稳定性。 提升鲁棒性:将大问题分解为小问题,降低了单步决策的复杂性。如果某个子任务失败,影响范围相对可控,也更容易进行针对性的调整。 增强可解释性与人机协同:清晰的计划和分步执行过程使得 Agent 的行为更容易被理解和调试。更重要的是,任务的分解为用户在规划审批和执行监控等环节的参与提供了便利,用户可以对任务的执行步骤给出修改意见,从而实现更高效的人机协作,确保任务结果更符合预期。 这种”规划-执行”的思考框架因其在复杂任务处理上的卓越表现,已成为AI Agent领域广泛采用的核心策略之一。例如在3月份涌现并广受关注的通用AI Agent项目,如Manus、OWL、OpenManus等,均采用了这种方式对用户任务进行拆分和执行,充分展现了其普适性和高效性。